Vaibhav Agrawal
I am a computer vision researcher. I am currently a master's student at CVIT (Center for Visual Information Technology), IIIT-Hyderabad, where I am fortunate to be advised by Ravi Kiran S (from CVIT) and co-advised by Venkatesh Babu Radhakrishnan (from Vision and AI Lab, IISc Bangalore). I am interested in computer vision and generative models. Recently I have focused on controlling generative models. I am also interested in the broader applications of generative models for various perceptual tasks in computer vision.
When I am not working, I am usually listening to music or playing the piano. I love receiving emails and messages! Hence, feel free to reach out to me in case you have any questions or suggestions about research.

Updates
- Sep 2025: Our team won the second prize at Gyan-Setu: National AI Innovation Challenge for India’s Manuscript Heritage. Great honor!
- Mar 2025: Our paper Compass Control was accepted to CVPR 2025. 🎉 See you in Nashville!
- Dec 2024: Presented LineTR at ICPR 2024 in Kolkata.
Research
I am interested in computer vision, broadly. Recently I have been working on controlling generative models. I am also interested in the broader applications of generative models for various perceptual tasks in computer vision.
* denotes equal contribution.

A method for multi-object orientation control in T2I generation. We learn an encoder that can map an input 3D pose to a special token to control an object, and show that the attention maps of these tokens can be constrained spatially to enable disentangled multi-object control.

Treating text-line detection as a segmentation problem discards various inductive priors, and hampers OOD generalization. We parametrize text-lines as geometric structures, and learn a DETR-style network to predict these parameters instead.
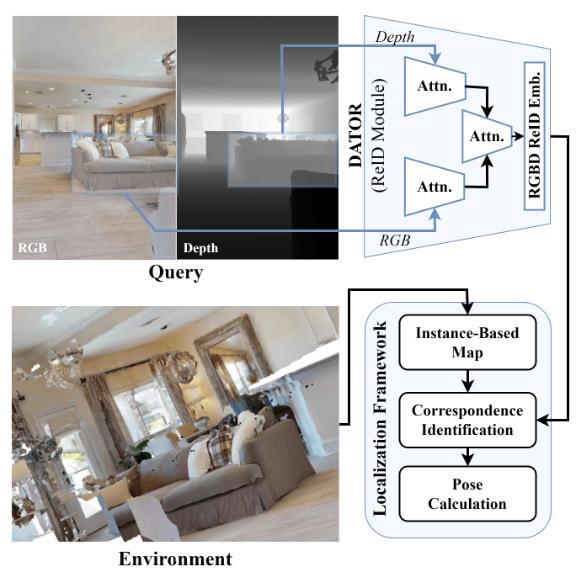
We train a multi-modal (depth + RGB) network to perform the object re-identification task. Modality dropout ensures robustness to failure of one of the modalities. We demonstrate application of the model in a downstream SLAM pipeline.